
2018/04/05
異なるJiraサーバー間でデータ同期させて、チームのプロセスを活性化させましょう:Exalate issue sync



Author
山本 鮎美Ayumi Yamamoto

こんにちは!
リックソフトの山本です。
Atlassian製品を愛用中の皆様は、製品の良さはどんな所だと感じているでしょうか。
私も色々感想はありますが、何といっても敷居の低さは大きなメリットのひとつだと思っています。
10ユーザーで月10ドルから始めることができて、テンプレートを使えばインストールしてすぐにでも使えるので、ひとまず自分のチームで試してみよう、という形でスタートするケースも少なくないですよね。
これは良い!となれば、他のチームにお勧めしたり利用者を増やしたりと、全社規模になっていったりすると思います。
ただ、拠点や運用方法、はたまた予算の都合で、国内のJira、海外のJira、〇〇事業部のJiraなどと、気付いたら会社の中に複数のJiraがあり、各々がそれなりの規模・・・。なんて事もあり得ます。
所属や拠点は違えど、同じ会社なら連携が必要な場合も出てきますよね。
今回は、異なるインスタンス間でJiraの課題を同期できるアドオン、「Exalate issue sync」を紹介したいと思います。
2011年にスタートしたiDalkoというベルギーの企業が開発しているアドオンです。
これを利用すると、一方のJira課題の情報によってもう一方のJira課題のステータスを遷移させたり、フィールドの値やコメント、添付ファイル等も同期させる事ができるので異なるJira間で課題を共有する必要がある以下のような場合に、よりタイムリーに仕事を進めることが可能になります。
- ユーザーからのバグ報告や問い合わせ用と開発用のJiraが別に存在していて、それぞれの情報を連携する場合
- 海外にも開発拠点があり、それぞれJiraで管理しているが開発チーム同士で連携する場合
- Jiraを持つ複数の企業で1つのプロジェクトを実施する場合
同期の仕組み
ここからは、同期の仕組みについて少し詳しく説明したいと思います。
公式のドキュメントだけで検証しようとして、私はここを理解するのに一番苦労しました。
Exalateでの課題同期における重要な要素は、インスタンス、トリガー、リレーション、レプリカの4つで、同期の流れは以下の図の通りです。
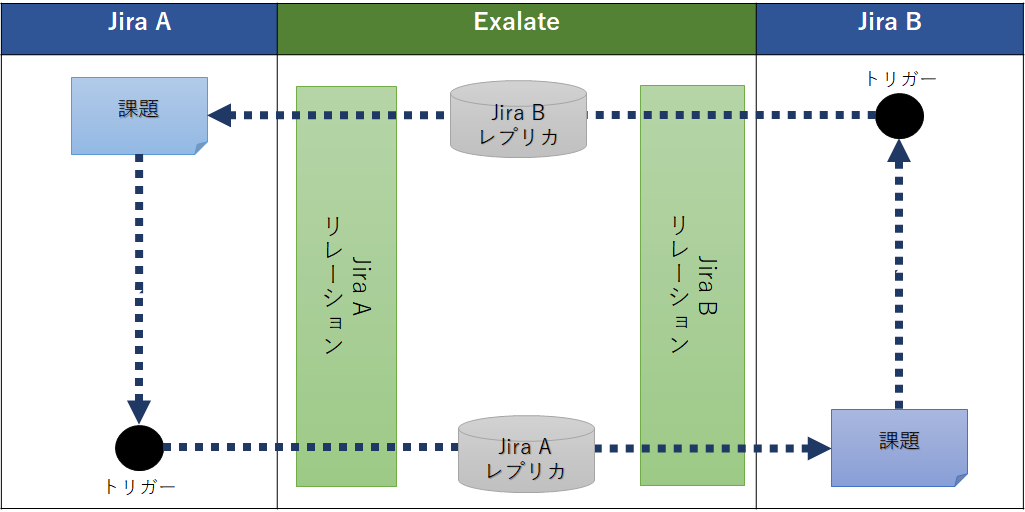
インスタンス
文字通り、同期する相手Jiraの情報です。
複数追加することができ、認証の有無が選べます。
トリガー
同期処理を開始させるイベントを、トリガーと呼びます。
トリガーは、以下のパターンで発生します。
- 事後処理に同期実行を指定したトランジションが実行された
- ユーザーが課題のメニューから手動で実行した
- 指定したJQLと課題が一致した
- 同期済みの課題が更新された
トリガーが発生すると、リレーションと呼ばれる同期処理が呼び出されます。
リレーションとはGroovyベースのスクリプトで実装する、同期において要の設定です。
リレーションとレプリカ
リレーションは同期する相手Jiraを指定して、双方に同じ名前で作成します。そうすることでインスタンス間で関連する同期処理として認識されます。
これを元に作成したレプリカ(課題のコピー)を使って課題を同期します。
リレーションは、レプリカを作成するData Filter、課題を作成するCreate Processor、課題を更新するChange Processorの3つから構成されています。
Data Filter
Data Filterはフィールドの値やステータスなどの相手のJiraに渡す情報を、レプリカと呼ばれる課題のコピーに抽出します。
課題はissue.と、レプリカはreplica.と示し、続いてシステムフィールドの場合はそのまま名前を、カスタムフィールドの場合は.customFields.”<フィールド名>”と指定します。
例えば以下のように記述すると、JiraAから要約と説明とカスタムフィールドのCategoryを持つレプリカが作成されます。
Jira A
replica.summary = issue.summary
replica.description = issue.description
replica.customFields.”Category” = issue.customFields.”Category”
Create Processor
Create Processorは、同期済みの課題が存在しない場合に、レプリカを元に同期先で課題を作成します。
課題が作成されると、ツイントレースと呼ばれるリポジトリに課題のペア情報が格納されます。
課題はissue.と、レプリカはreplica.と示し、続いてシステムフィールドの場合はそのまま名前を、カスタムフィールドの場合は.customFields.”<フィールド名>”と指定します。
フィールド指定の仕方はData Filterと同じです。先ほどJira Aで登録したフィールドの値をもとにJira Bで課題を作成するには以下のようにします。
Jira B
issue.projectKey = “Ricksoft”
issue.typeName = “QA”
issue.assignee = “yamamoto”
issue.summary = replica.summary //Jira Aの要約を入力
issue.description = replica.description //Jira Aの説明を入力
issue.customFields.”Category” = replica.customFields.”Category” //Jira AのCategoryを入力
課題を作成するので、当然プロジェクトと課題タイプを指定しなければなりません。
サンプルでは直接指定していますが、応用すれば、Jira Aのフィールドに入力された値を元にプロジェクトと課題タイプを指定することもできますよね。
Change Processor
Change Processorは、同期済みの課題が存在する場合に、レプリカを元に同期先の課題を更新します。
以下の例では、同期されたJira Bの課題がクローズすると、Jira Aの課題もクローズします。
※Jira BのData Filterでステータスと解決状況をレプリカに抽出する必要があります。
Jira A
//Jira Bの課題のステータスがCLOSEDの場合
if (replica.status.name == “CLOSED”) {
//Jira Aの課題でトランジション「Close Issue」を実行し、解決状況を設定
workflowHelper.transition(issue, “Close Issue”)
issue.resolution = replica.resolution
}
workflowHelper.transitionというのは同期スクリプトを簡素化するためのExalate独自のメソッドです。この他にも色々なHelperメソッドがあります。
以上、Exalateアドオンでの同期の仕組みを中心に説明しました。
いかがでしたしょうか?
複数Jiraを持っていて連携を諦めていた方も、Jiraの同期とは興味があるなという方も、Exalateアドオンの導入を検討されてはいかがでしょうか?
評価版のご要望やその他の問い合わせはこちら。
Atlassian Marketplaceからダウンロードいただけます。